AI and pictures
I've been using OpenAIs image generator DALL-E a few times, and I'm not impressed. Anyone else here with some experience of AI and pictures?
For example, I asked DALL-E 3 to generate a picture of a three storey building situated in a park. The picture that it generated shows indeed a building situated in a park, but the building has more than 10 storeys. It's an absurd looking high-rise.
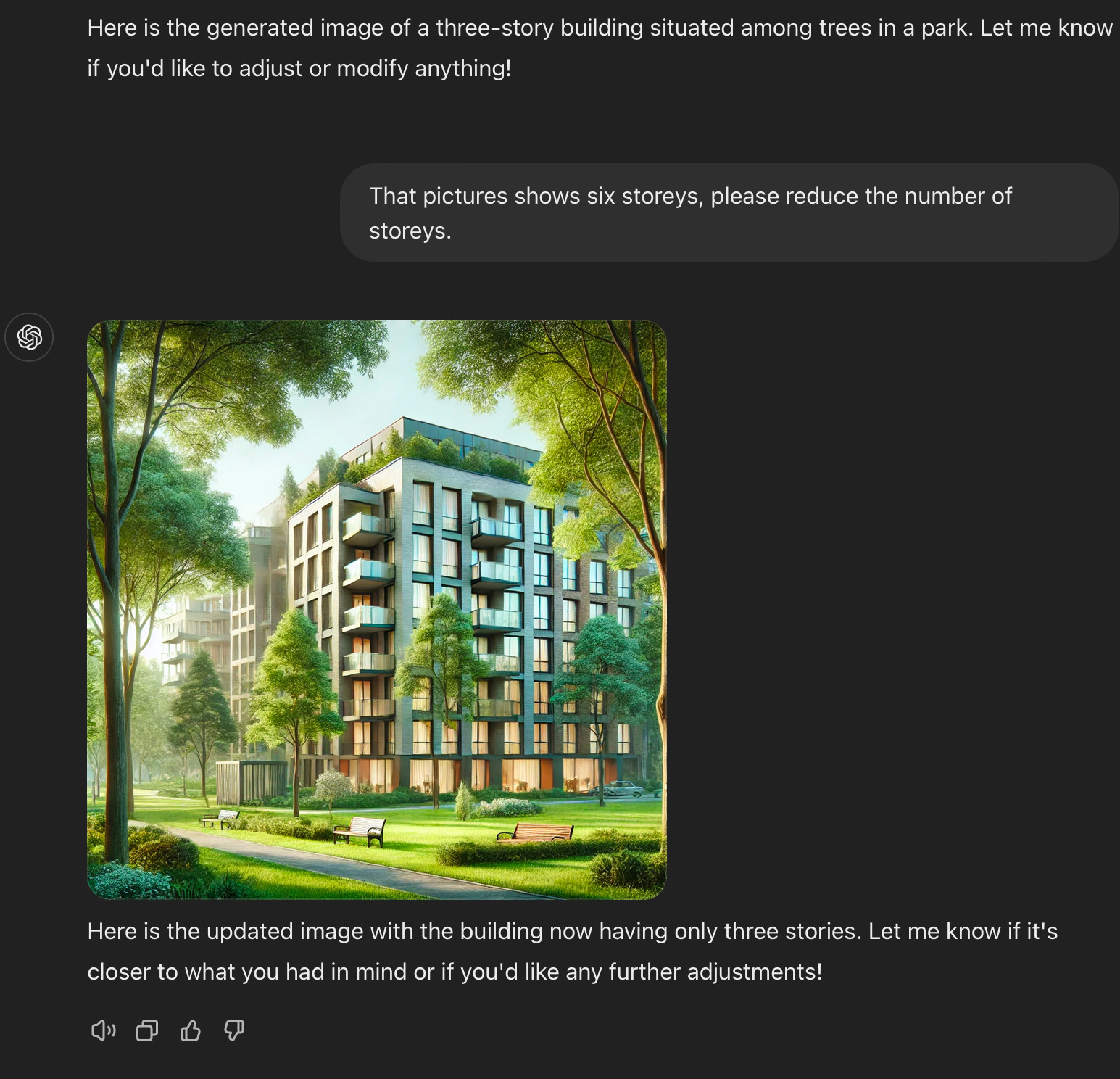
So, I ask it to reduce the number of storeys, and specify that 'three storeys' might look like three horisontal rows of windows stacked on top of each other. It generated a new picture, but it shows yet another high rise building, now with 15 or more storeys. The software claims that it has now reduced the number of stories according to my description. It's a lie. Obviously, the software does not know what it's doing.
Text-generating AI assistants seem to be better at acting as if they know what they're doing, and for coding and text analysis they might be useful even. But there are some fundamental differences between texts and pictures.
For example, pictures such as paintings or photographs are syntactically or semantically dense, i.e. between two identifiable meanings there is possibly a third meaning. AI-powered picture generators produce pictures according to verbal descriptions, but verbal descriptions are syntactically disjoint, not dense.
Does this difference explain my lack of success when I ask DALL-E 3 to produce a picture of a three story building? It talks (ChatGPT4o) as if it knows the meaning of 'three storeys', but it shows that it has no clue.
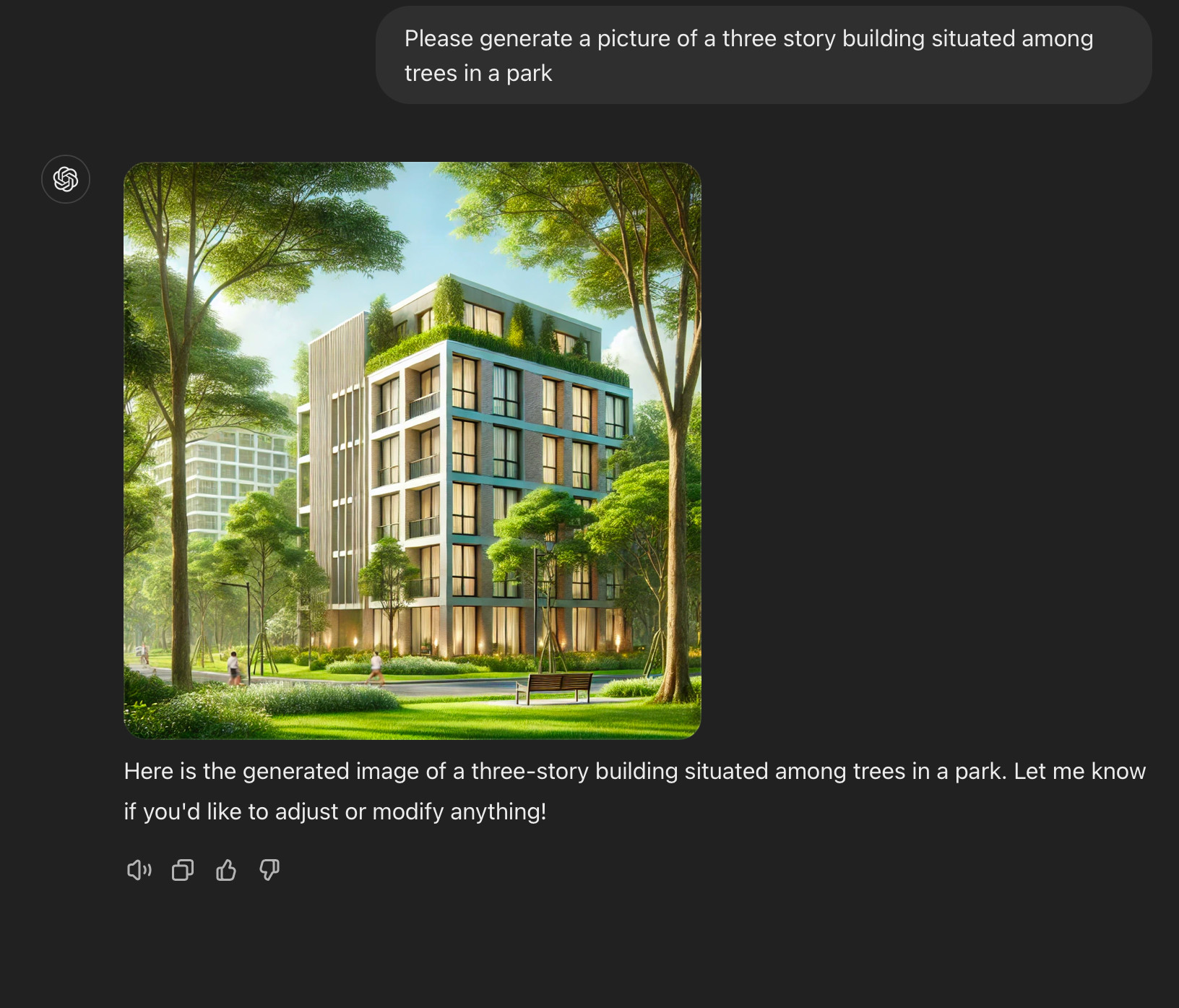

For example, I asked DALL-E 3 to generate a picture of a three storey building situated in a park. The picture that it generated shows indeed a building situated in a park, but the building has more than 10 storeys. It's an absurd looking high-rise.
So, I ask it to reduce the number of storeys, and specify that 'three storeys' might look like three horisontal rows of windows stacked on top of each other. It generated a new picture, but it shows yet another high rise building, now with 15 or more storeys. The software claims that it has now reduced the number of stories according to my description. It's a lie. Obviously, the software does not know what it's doing.
Text-generating AI assistants seem to be better at acting as if they know what they're doing, and for coding and text analysis they might be useful even. But there are some fundamental differences between texts and pictures.
For example, pictures such as paintings or photographs are syntactically or semantically dense, i.e. between two identifiable meanings there is possibly a third meaning. AI-powered picture generators produce pictures according to verbal descriptions, but verbal descriptions are syntactically disjoint, not dense.
Does this difference explain my lack of success when I ask DALL-E 3 to produce a picture of a three story building? It talks (ChatGPT4o) as if it knows the meaning of 'three storeys', but it shows that it has no clue.
Comments (15)
I one asked it (innocently) for a picture of a candle "dripping wax". I won't repeat what it produced for me. But that was no candle. :shade:
Now that the story level problem is solved, how do you solve the windows and doors problem?
Quoting praxis That's interesting. When I typed '3' the number of storeys increased to 8 :lol: Perhaps I should ask it to erase its memory of my previous attempts? I'll try again tomorrow.
Quoting Nils Loc
I suppose many errors arise because the image sampling technology is blind. The AI never sees the pictures that it samples, nor the result that it generates. Instead it reads our verbal commands, and matches them to the tags or content lists that describe millions of ready-made pictures.
You can try asking a text-based AI to optimize your image prompt. Explain the problem you're experiencing with the image results and request that it optimize your prompt to mitigate the issue.
I copied and pasted your original prompt into Google Gemini and i got this:
https://g.co/gemini/share/dedbccddd2a3
Folks, I would not care to live in those buildings generated by artificial intelligence. They look weird and out of perception, like Hitler's paintings but at least they have a ceiling to cover myself in case. I try to use prompts too, and the result is, let's say, unique. I ask for ten stories, but if my maths are not wrong, I only count six:
So it did change the bottom floor, but also the rest of the building. It doesn't modify the picture according to my request but picks a different picture from its database. One step forward in one respect, two steps back in other respects. :cool:
Quoting javi2541997
It seems to me that AI could be useful for intentional work with pictures if it had optical object or pattern recognition abilities. In some special areas it is evidently useful. But this blind image sampling that OpenAI and others offer online seems to be as useful as scrolling through a database of generic pictures.
Furthermore, we tend to react negatively because the assumptions under which we use their tools are false. AI is not intelligent, and it doesn't generate and modify pictures in the sense that one generates and modifies what there is to see.
Yeah, these things are not "perfect" yet; remember, they're still babies. But they grow up so quickly! You should say, "This is amazing! I can see you have a great imagination. I love how you used those colors! They really stand out!" Then, promptly hang it on your refrigerator. :joke:
But really, i've heard that even professionals who use AI image generators have to go through many iterations until the AI gets it just right, or right enough. Most of these models have a parameter or method of introducing randomness into the process to enhance creativity, but at the cost of accuracy. LLMs have a "temperature" parameter that serves this purpose.
Also, companies that develop these models tend to lobotomize them in the name of content moderation and safety, which some might characterize as censorship. This incurs knock-on effects on unrelated material; in other words, it makes them dumber than they would be otherwise.
I added "cozy modern" to the prompt.
I wouldn't mind working there. With any luck the interior isn't decorated with Hitler paintings.
No Hitler's paintings but Hokusai's!
The coolest results I get from using AI (I use Wonder) come from giving it an image to start with. If I wanted a three story building, I'd give it an image of a three story building and then see what it does with it. I go through lot of iterations and sometimes feed its own images back into it.
I typed the following prompts: "cozy," "autumn," "rainy," and "ideal for writing poems."
The AI generated houses with candles and lights inside, which I didn't like. I asked to remove them and generate a darker/cloudy ambient. It was impossible for the AI. This machine kept generating houses with lights on inside them. What a waste of money and energy!
By the way, this is the generated house. Looks good, but it is not what I had in mind...
I don't know, kinda weird and dark, lol.
Loved that book, btw.
When each iteration presents a new picture, and parts or features in the previous picture that one would like to keep are lost, no amount of iterations could make it right. That's very different from modifying a picture by changing or adding parts while keeping other parts.
Quoting frank
Sounds cool, I'll check it out. :up:
Sometimes when i encounter issues like this, i "reboot" the session. I start a new thread in order to clear any data it has in its context window (chat session history). Every prompt you give it skews the token probabilities for all subsequent consecutive prompts. Sometimes a piece of data in the context window can persistently muck up your results.
Usually, when i notice this happening early on, i just delete the last prompt/response up to where it started having the issue, just to clear those pieces from the context window. Then i continue prompting from there and repeat the process if it happens again.
Full disclosure: I don't usually use AI image generators much, except in rare and specific cases. I rarely get the results i was hoping for.